Methodology
This extended research study builds upon our previous work, incorporating new data sources and employing advanced analytical techniques to better understand the risk factors associated with patient readmission. The initial focus is on integrating new patient records with existing data to confirm and enhance previous results, demonstrating the robustness of these findings. The next step, or our primary objective in this work is to conduct an in-depth feature importance analysis and translate it into concrete and actionable recommendations for CHWs using observed statistics as well as learned features based on supervised and unsupervised machine learning.
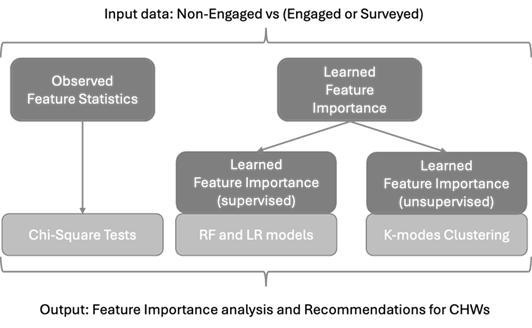
In order to better define our methodology, we need to first describe our data. Crucially, we have categorized the patients based on their levels of engagements with the CHWs. This was done in an attempt to acknowledge and characterize an observed implicit selection bias in the patient base. There is an underlying difference between patients who chose to engage with CHWs and those who do not, i.e., as we will show below, readmissions are better “predicted” for the former than the latter even before considering additional data collected from CHWs. Therefore, in order to make the case that these additional data make a positive difference in model accuracy, we need to establish a reference accuracy that takes into account the different characteristics of patients at baseline. Figure 1 first describes the raw data and the available data for different types of patients based on levels of engagements, while Figure 2 describes our methodology based on the levels of engagements.
Observed Feature Statistics
To establish a baseline understanding of readmission patterns, we examined the raw dataset before applying any machine learning techniques. Observed readmission rates were calculated for each patient group:
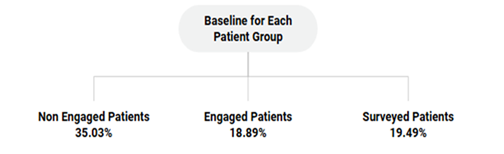
This analysis supports our primary hypothesis that engagement with CHWs significantly reduces readmission rates. Furthermore, demographic comparisons revealed that the 'High-risk readmit' factor was a predominant predictor of readmissions in the Non-Engaged group. These baseline statistics serve as critical benchmarks against which we compare the learned results from supervised and unsupervised models.
Supervised Learning Classification and Feature Importance
In previous work, we defined a classification (supervised learning) problem of high-risk patients who are readmitted to the ED. In order to demonstrate the positive impact of the CHW program on ED readmissions, we set out to predict readmissions and show that:
- classifier's ability increased with engaged patients using CHW and SDoH data
- important features included CHW/SDoH related features.
Towards this goal, we used three types of classifiers:
- Logistic Regression (LR) model which was more commonly used in the previous works related to SDoH data
- Random Forest (RF) model - RF models are commonly used due to their predictive power, ability to deal with noisy data and crucially their ability to give feature importance. It is also possible to get feature importance from LR models.
- Neural Networks classifiers - Neural Networks (NNs) are powerful classifiers that have been shown to achieve higher accuracy and are increasingly being leveraged in health informatics.However, they typically require large amounts of data.
Our previous work showed that the RFs models consistently outperformed models, likely due to oversimplification in the case of the LR models and the lack of training data in the case of the NNs. Nevertheless, because we are now more interested in feature importance, we re-ran our experiments (30-run classification experiments using 80% training, 20% testing) using the RF and LR models.
Unsupervised Learning: K-Modes Clustering and Feature Importance
To gain further insights into patient subgroups and identify the characteristics of high-risk patients, clustering was employed to explore latent structures or natural grouping within the patient data given all available data and features. The goal was to identify any additional insights from subgroups within the population that might reveal different patterns with respect to features or readmissions and require different intervention strategies.
Partitioning clustering, exemplified by the widely used k-means algorithm, is a cornerstone technique in data analysis and machine learning, finding applications across diverse fields such as image processing, market segmentation, and bioinformatics due to its simplicity and efficiency. K-means however is designed for continuous features. Given the predominantly categorical features in our dataset, we discretized the rare continuous features such as age and time spent looking for resources and utilized K-modes clustering instead. The k-modes algorithm is an adaptation of k-means designed specifically for clustering categorical data, addressing the limitations of k-means, which relies on numerical distance measures like Euclidean distance that are not suitable for categorical attributes. Since we had defined “engaged” by at least some interaction/contact with CHWs, and surveyed as having answered at least one SDoH survey question, we expected some variability amongst these patients, hence some limitation of the supervised learning approach.. The goal of the unsupervised learning was to uncover similarities between patients and lead to a useful subgroup analysis of clusters of patients based on patterns in their demographics, levels of engagement, SDoH needs and/or readmissions risks.
We used the Elbow method to determine the optimum number of clusters. Feature importance in clustering would then consist in the characterization of “interesting” and “relevant” clusters.
Combining insights from observed statistics and learned feature importance
The methodological framework employed in this research aims to highlight the value of combining multiple data sources, statistical observations and feature importance from both supervised and unsupervised approaches to gain deeper insights into patient readmission risks. We hypothesize that some feature importance will emerge as overlapping across approaches, others will be discovered thanks to the particularity of each different model.