Data Collection
The dataset for this study consists of 2,173 patient records, each with 315 features encompassing demographic information (e.g., age, sex), referral details (e.g., high-risk based on social worker assessments, discharge from the ED), Community Health Worker (CHW) contact logs (e.g., number of calls, length of calls), and Social Determinants of Health (SDoH) data (survey answers about food or housing insecurity). The data set is a collection of patients from Mt. Sinai and Holy Cross hospitals and were generally referred to the Sinai Urban Health Institute (SUHI) by social workers between July 2020 and February 2024. Originally, CHWs were stationed in the ED, but COVID made that impractical. Starting in January 2022, SUHI’s CHW program expanded their referrals to include behavioral health patients and proactively reaching out to in-patients. The proactive outreach consisted in internally searching the Sinai Health Systems database for patients who had had 3 or more rounds to the post discharge program, i.e., they were repeatedly referred to CHWs by social workers. Additionally, starting in April 2022, SUHI slightly expanded the set of SDoH variables.
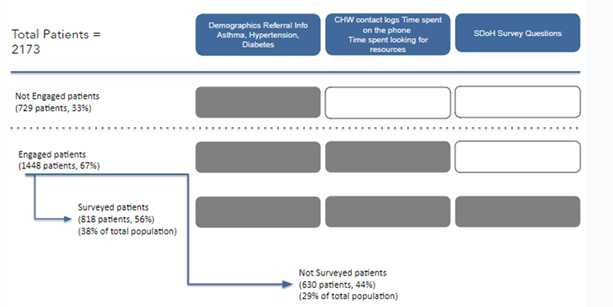
As illustrated in Figure 1, the dataset comprises three distinct patient groups:
- Non-engaged Patients: Consisting of 729 patients (33% of the total population), these individuals had no recorded engagement with CHWs.
- Engaged Patients: Consisting of 1,448 patients (67% of the population), these individuals had documented interactions with CHWs. This group was further divided into:
- Not Surveyed Patients: Comprising 630 patients (44% of engaged, 29% of total population), these patients interacted with CHWs but did not participate in the SDoH survey.
- Surveyed Patients: A subset of 818 engaged patients (56% of engaged, 38% of total population) who completed at least some portion of the SDoH survey, providing additional insights into their social environment and health status.
Data Integration and Preprocessing
To ensure consistency and reliability of the dataset, several preprocessing steps were carried out:
- Data Cleaning :
The raw data contained several missing values, duplicate entries, and inconsistencies. Missing data was addressed through a combination of imputation techniques and removal of incomplete records where appropriate. Specific columns with a high number of missing values were flagged for possible omission or imputed using the mean/mode value depending on the feature type. - Normalization and Standardization :
Continuous variables were normalized to bring them to a common scale, ensuring that features such as patient age, CHW contact duration, and SDoH scores were consistent and comparable across the dataset. Standardization was used to facilitate effective training of machine learning models, particularly those sensitive to feature scaling such as Logistic Regression. - Feature Engineering :
Feature engineering was conducted to enhance the dataset’s predictive capacity. Interaction terms were created to capture complex relationships between features such as the frequency of CHW contact and patient comorbidities. Derived variables were also generated from CHW logs, such as the total time spent with CHWs and the total number of contact attempts. Additionally, binary indicators were used to represent the presence or absence of specific SDoH conditions, which allowed for more granular analysis. - Data integration of the new patients :
Most new SDoH features (added after January 2022) were present in the previous dataset. For new features such as emotional health, survey answers (e.g., anxiety, depression or loneliness) were combined and added based on the number of missing values to limit the number of Not Available (NA) values in the entire dataset